
¿Qué es una araña web?
 Un spider, araña web, crawler, rastreador o bots son unos programas que inspeccionan todas las páginas web existentes en el mundo de forma automatizada.
Un spider, araña web, crawler, rastreador o bots son unos programas que inspeccionan todas las páginas web existentes en el mundo de forma automatizada.
Su función es la de rastrear las páginas web para indexarlas, es decir, que aparezcan en los índices de búsqueda del buscador en concreto que estemos usando (Google, Yahoo, Bing…)
Además, buscan documentos del tipo que sean (html, pdf, imágenes, etc.) donde se incluyan determinadas palabras clave para luego mostrarlos en las búsquedas de los usuarios.
Una vez recolectados todos estos documentos o datos, el motor de búsqueda crea consultas sobre estos.
Los principales motores de búsqueda en la Web tienen un programa de este tipo, que también se conoce como un «rastreador» o «bots».
Cuando hacemos una búsqueda lo que realmente ocurre es que le planteamos una consulta al buscador.
Es en este momento cuando busca entre todos los datos recolectados de las distintas páginas web y nos muestra los que son acorde a nuestra búsqueda. Los que dan una solución a nuestra consulta.
¿Por qué es necesario un archivo robots.txt?
Todas las páginas web o la gran mayoría tienen en su código un archivo llamado robots.txt a través del cual especifican que páginas web quieren que sean rastreadas y cuáles no.
No es obligatorio, pero si recomendable, ya que esto le hará más fácil al buscador el rastreo de tu página web, de qué quieres que puedan ver los usuarios y qué no.
Es decir, si no queremos que lea algo en concreto debemos indicarlo.
Por ejemplo, no es necesario que Google lea nuestra política de privacidad.
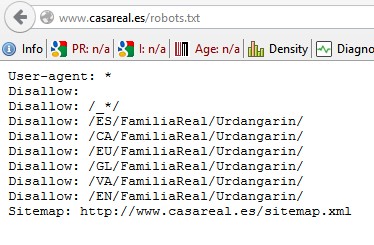
Un ejemplo puede ser los robots de la página web de la casa real. Si entras en la web http://www.casareal.es/robots.txt podrás ver como para todos los idiomas, la casa real ha impedido que se encuentre información sobre Urdangarin en su página web.
Errores que se dan al no tener un archivo robots.txt o tenerlo mal desarrollado
1. Si no tienes un archivo robots.txt significa que tu página está completamente abierta para que cualquier ‘araña’ la rastree.
Si tienes una web sencilla, estática con nada que ocultar esto no es un problema, pero teniendo en cuenta que hoy en día la mayoría de las páginas web se hacen a través de un CMS o gestor de contenidos como puede ser WordPress, es probable que si quieras hacerlo.
Simple y llanamente porque de esta manera evitaremos duplicación de contenido o que los usuarios vean partes del back-end (código de la web) y partes de tu página que no están destinadas a tus visitantes.
La duplicación de contenido es un problema ya que confunde a los rastreadores para que puedan saber cuál es el contenido auténtico / único.
Por ejemplo:
Si coges una noticia de un diario cual sea y la copias en tu página web, lo más probable es que te penalicen porque estás duplicando contenido.
2. Dejar este archivo en blanco, tampoco ayuda.
No ayuda porque esto deja tu web igualmente expuesta a todos los rastreadores, dejando que indexen url’s que no queremos que se vean.
3. Archivos robots.txt por defecto
Siguen suponiendo un problema, porque de nuevo, tu página queda igual de desprotegida que en los anteriores casos y no tiene sentido alguno.
4. Que tu mapa web contradiga tu archivo robots.txt
Si tu archivo robots.txt y tu mapa web se contradicen llevarán a error al buscador. Créeme, nada bueno.
Si el sitemap.xml tiene URL’ s específicamente bloqueadas en el robots.txt, el buscador acabará por no indexar nada de tu página web y no te mostrará en sus resultados.
A menudo, esto puede ocurrir si el archivo robots.txt y / o archivos sitemap.xml son generados por diferentes herramientas automatizadas y no controlados manualmente después.
5. Si hay algo que no quieres que absolutamente nadie vea, no lo pongas en el archivo robots.txt
Pese a que en un principio todo lo que esté en ese archivo no se indexará, no significa que no haya ‘arañas’ que no lo tengan en cuenta.
Esto es porque, hay algunas arañas que “van por cuenta propia” es decir, son programas creados que funcionan de manera automática y no siempre hacen caso de las indicaciones ni protocolos.
Además, cualquier usuario puede ver en tu archivo robots aquello que estas bloqueando.
Por lo tanto tienes dos opciones, protege esa parte de la web con contraseña, o la otra opción es: si hay algo que quieres que permanezca completamente privado, NO lo subas a internet y te ahorrarás problemas.
¿Conocías ya las arañas web? ¿Has tenido en cuenta el archivo robots.txt al desarrollar tu web? ¡Cuéntanos tu experiencia!







Pingback: Como rediseñar tu web sin cargarte el SEO - TresdeSEO